If you've worked with medium/large datasets, large projects, and/or slower hardware (e.g., a laptop), you may have wished computations were faster. To improve the speed of computations, it may be useful to create a second working copy of the dataset which contains a small (random) subset of records. You would use this smaller dataset until you get everything built and formatted. Then, when you are ready to publish, switch to your live dataset and export.
The following documentation applies to both SPSS (by IBM) and PSPP (a free GNU alternative to IBM's SPSS). The screenshots shown here are taken from GNU PSPP.
In the top menu of PSPP (or SPSS), click Data > Select Cases...

Select "Random sample of cases" and click the "Sample..." button.
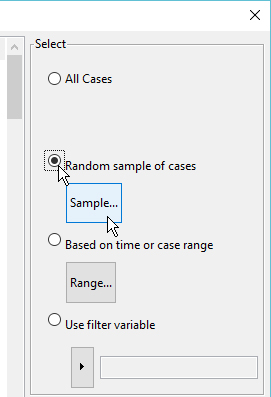
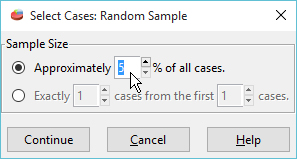
Type in the percentage of records you want to save. Use your judgement to include as few records as possible without causing too many missing values or Low-N effects.
Be sure to specify that unselected cases are to be "Deleted". Otherwise your changes will have no effect in Report Builder. (We'll end up saving this under a new filename).
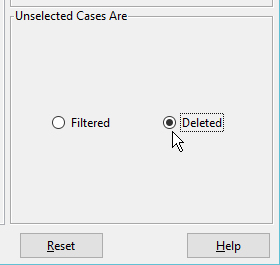
Click OK.

Click "Save As..." and append something like " (5pct)" to your filename.
Now use the " (5pct)" working copy of your dataset in RB until you are ready to officially publish. When you are ready to publish, switch to your live dataset, export, and maybe get a soda while you wait.
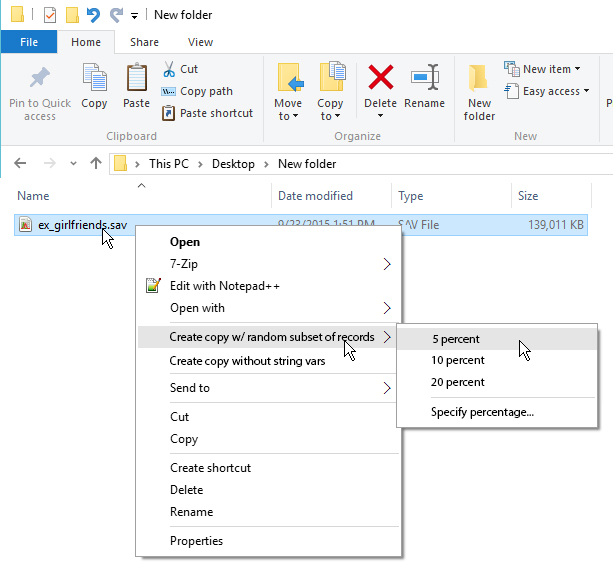
We've considered adding an Explorer file handler so that in Windows File Explorer you can right-click on a file and "Create Random Subset > 5 percent". Would you appreciate this feature? If so, let us know and/or vote for it here. Thanks!